
Digital Repository Service and Metadata Attribution
As part of our initial analysis of the East Boston Community News, we decided on starting with running some form of named entity recognition on the 471 issues of the newspaper. The collection is currently digitized as part of Northeastern University Library Archives and Special Collections and is maintained through the Digital Repository Service (DRS) at the Northeastern University Library. In order to pull the most amount of data from the existing files, we first had to understand the database hosting those files, including data models, file structures, and naming conventions. As part of the digitization process–and eventual ingestion into Northeastern’s larger repository–the issues were all uploaded as OCRed, machine-readable PDF files and a few associated IDs. Knowing how the DRS assigns filenames to digital objects that have been ingested was crucial to our analysis. Because Northeastern’s DRS uses Fedora, an open source repository platform used in libraries, we had to be attentive to the ways in which Fedora handles ID assignment. A file in Fedora, has multiple components, including the file object(s), metadata objects, and other items (like thumbnails). The primary component of the file, what’s referred to as the core file, is created when new items are ingested into the DRS along with other elements of the file, called content objects. Each of these components are assigned a PID (unique persistent identifier), and those PIDs ultimately become the filename for the PDF file in the DRS, while the original filenames prior to ingestion were the relevant dates for each file.
In order to maintain “Date” as a metadata category in our list of named entities, I had to retrieve the date from the XML files generated for the metadata in the DRS and map those dates to a filename. Since the PDF file name is the same as the last portion of the URL for the object in the DRS, mapping dates to individual entities from a particular issue of the newspaper was a matter of maintaining the relevant PIDs throughout the code. When the final CSV file is generated after the NLP analysis of the newspapers, the dates are then added to the CSV under a column named “date,” as well as the page number from which that particular entry in the CSV was pulled. Since most NLTK processes do not automatically provide this crucial metadata as part of their automatic NER output, I developed a workflow for tracking and including the date and page number for each entity.
Named Entity Recognition with NLTK and Spacy
Named entity recognition is an essential processing step for any form of natural language processing. In the last decade, using the Natural Language Toolkit (NLTK) to detect English languages has become somewhat of a closed case. NLTK is one of many tools for extracting named entities, though it is popular in part because it contains libraries for nearly all NLP tasks. As Manning (2011) writes, Part-of-Speech tagging has reached an accuracy rate of 97% with English languages and while going beyond 97% accuracy still seems out of reach, those numbers are still significant. However, as Tena Belinić writes, when it comes to processing non-English languages, the task becomes much more difficult. As Al-Rfou, et.al argue, “applying these approaches to a massively multilingual setting exposes two major drawbacks; First, they require human annotated datasets which are scarce. Second, to design relevant features, sufficient linguistic proficiency is required for each language of interest. This makes building multilingual NER annotators a tedious and cumbersome process.” The East Boston Community News often contains a significant portion of the paper written in Italian and preserving the significance of this portion is integral to performing named entity recognition for this project.
In order to test the efficacy of named entity recognition (NER) on the East Boston Community News, which as previously noted is a OCRed newspaper, I first began by writing some code that would process each page of each issue independently. Using the Python package PyPDF2, which makes working with PDF files in Python relatively simple, also preserves page numbers. Page numbers are an essential metadata category for text analysis on newspapers. By preserving the page number from which a named entity was pulled, we are able to not only determine which entities most frequently appear in the newspaper, and in which years, but we are also able to isolate, say, the front page entities from entities that appear on the last page of the newspaper. Once the PDF files were read and content was sorted according to date and page number, I then needed to decide which of the numerous packages and tools for NER would be most beneficial to this project.
Initially, I decided to start by using the NER capabilities of NLTK. NLTK supports NER for multilingual documents, which is essential for analyzing the portions written in Italian in the East Boston Community News. However, because NLTK contains text processing libraries, and because its aim is to split a text up into sentences in order to analyze sentence structure, it performs pretty well when it comes to sentence tokenization. When performing NER, NLTK separates a sentence into chunks according to patterns in parts of speech used in the sentence. Significantly, chunks will not overlap, just as a tokenizer will not tokenize in such a way that sentences overlap with each other. Since NLTK is looking for named entities, the chunker will pay particular attention to noun usage. The noun patterns that the chunker pulls out are called Noun Phrases (or NP). The chunker will split noun phrases up into their smallest parts, so a noun phrase parsed out by the chunker will not contain other noun phrases embedded within it.
Once the sentence is split into chunks, those chunks can be represented as a tree, where the root is denoted with ‘S,’ for ‘sentence,’ and each of the chunks occupy a different branch. The chunk branches also contain leaves, and each of these leaves represent a single word or phrase in the chunk. From this tree, a classifier can then pull named entities and assign them a label of Geopolitical Entity (GPE), Person (PERSON), Organization (ORGANIZATION), Facility (FACILITY), or Location (LOCATION).
The general transformation that NLTK makes on natural language, is a transition from unstructured data to structured data. The following figure from NLTK’s documentation illustrates this transformation:
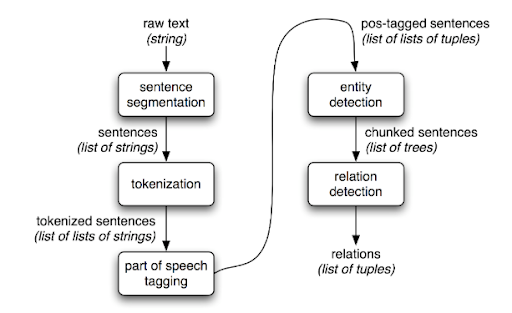
When initially performed on the entirety of the East Boston Community News, it was difficult to get the chunker to recognize a person’s first and last name as combined entities, rather than separate entities. Since person names were an essential part of our intended analysis, it was crucial that I work around this problem. In order to solve this issue, I performed a join on any chunk branch leaves which shared the same entity label. For example, if John and Hancock appear next to each other in the same branch, and both are labeled PERSON, then they were joined to become the entity John Hancock. Additionally, I found that NLTK entity recognition often made mistakes when it came to identifying the correct label for an entity. The mistakes occur often enough that while we have a substantial dataset, the mistakes could potentially negatively influence our results. Additionally, the runtime for NLTK on all 471 files was particularly slow. Running any iteration of the code could take upwards of five hours to complete. We could easily imagine a scenario where we could be working with even larger datasets, and so we ultimately decided that the best strategy would be to look for other packages for performing NER. Finally, NLTK is not opinionated, which means that in general, rather than pick the single, most effective algorithms for its tools, NLTK contains many algorithms from which to choose. Some pros to using NLTK include its capacity for multilingual named entity extraction, but this benefit ultimately was outweighed by some of the larger issues such as runtime and accuracy.
Following my use of NLTK, I decided to try running the named entity recognition feature of spaCy on the East Boston Community News. Unlike NLTK, spaCy is an opinionated package, which means that rather than contain many algorithms and leave it up to the user to pick a method, spaCy maintains and updates whatever is determined to be the best algorithm for a particular problem. However, because spaCy makes determinations about algorithm usage and doesn’t leave this choice up to the user, it is much faster than NLTK. In fact, two peer-reviewed papers in 2015 confirmed that spaCy offers the fastest synthetic parser in the world, and that its accuracy is within 1% of the best available. Additionally, the named entity labels that spaCy uses are more robust and descriptive than what is provided by NLTK. For example, labels produced by spaCy include DATE, TIME, MONEY, WORK_OF_ART, and others which provide us with more robust data with which to perform an analysis.
Unlike NLTK, which takes the approach of string processing, spaCy takes an object-oriented approach. Object-oriented approaches work by considering systems to be composed of objects, which can each be controlled in a modular way. For natural language processing, this approach means that the document, sentences, and words are each considered objects. Then, in order to annotate the document, spaCy uses a statistical model which makes a guess regarding which label most likely fits a specific context. Though spaCy was able to process our PDF files much faster than NLTK, it required a substantial amount of memory for the package to complete the task. SpaCy also includes an entity visualizer which allows for interactive entity exploration like in the image below:
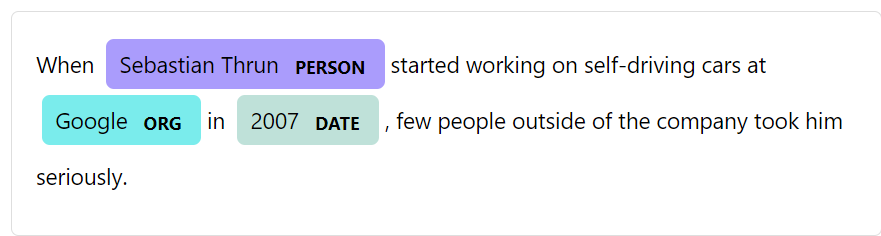
Ultimately, the major differences between spaCy and NLTK, are that NLTK was built primarily for educational purposes (i.e. NLTK is primarily designed to be used to develop prototypes and as a teaching tool) and while it is great for building on top of, since it offers support for many NLP tasks, in our case, we need something faster. SpaCy, on the other hand, is designed to get specific jobs done as quickly as possible. As Swaathi Kakarla writes, “while NLTK provides access to many algorithms to get something done, spaCy provides the best way to do it.” Both NLTK and spaCy have a capacity to recognize some non-English languages, including English, German, French, Spanish, Portuguese, Italian, Dutch, and Greek, but/however we must still examine whether accuracy is equivalent across packages. Additional costs must also be taken into consideration. For example, NLTK requires a substantial amount of time to run, and spaCy requires significant memory in return for its high speed.
Initial Results
The initial results of my analysis are detailed below. In order to compare the results of named entity recognition on the East Boston Community News with spaCy and NLTK, both resulting CSV files were cleaned using OpenRefine, an open-source desktop application for cleaning and organizing data. Often, because spaCy and NLTK were run on OCR’d text, there were places where variant spellings of words and phrases occurred. In order to calculate entity frequency, it was crucial that all entities had a standardized spelling and capitalization. OpenRefine’s edit and cluster feature makes standardization of spelling and capitalization a streamlined process. By grouping together data points that it suspects are the same, the cluster and edit function allows the user to review instances where, perhaps, two or more data points should be combined to form a standardized label. For example, there were many instances where East Boston could be spelled as EAST BOSTON, _East Boston, east boston, eastboston, etc. For these instances, it was important that the spelling and capitalization be standardized so that way a statistical analysis of the results would be legible and as accurate as possible. While this process was fairly quick for the NLTK CSV file, the spaCy file required some minor adjustments to the process memory. Since NLTK has fewer entity labels that spaCy, the NLTK CSV file was much smaller, so OpenRefine was able to handle its size out of the box. The spaCy file, however, was much larger so minor adjustments had to be made to increase OpenRefine’s memory allotment in the application’s settings in order to allow OpenRefine to access the appropriate amount of memory in order to handle such a large file.
Once the CSV files were cleaned using OpenRefine, I then used Tableau in order to get a basic analysis of the data. The functions of Tableau that I was using (primarily filtering and counting) could have also been achieved using Microsoft Excel, but the size of the CSV files made it difficult to achieve the same results quickly using Excel. Tableau, which is a data analysis and visualization tool, was quickly able to process these large CSV files and the ability to simultaneously toggle between and interact with various representations of a CSV file’s data made this tool ideal for an initial analysis of the results.
NLTK
As is illustrated in the chart below, NLTK calculated the occurrence of 555,418 entities over the span of the East Boston Community News’ 471 issues. These entities were separated into the respective categories that were discussed above. Notably, in some usages of NLTK, GSP (Geographical-Social-Political Entity) is replaced entirely with GPE (Geo-Political-Entity) rather than both of the labels existing separately. The Automatic Content Extraction (ACE) Project, a project whose focus is on developing extracting technology for natural languages is the source of the corpus that NLTK’s chunker is trained on. Eventually ACE phased out GSP with GPE, though the appearance of both tags in the results of NLTK’s NER suggests that, perhaps, NLTK is trained using all materials from the ACE Project rather than the most recent phase materials, though how NLTK chooses between GPE and GSP is not clear. The ACE Project’s phase documentation explains in more detail the various phases of the project.
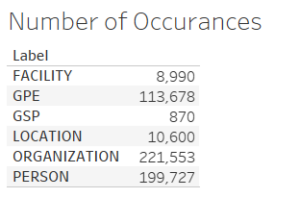
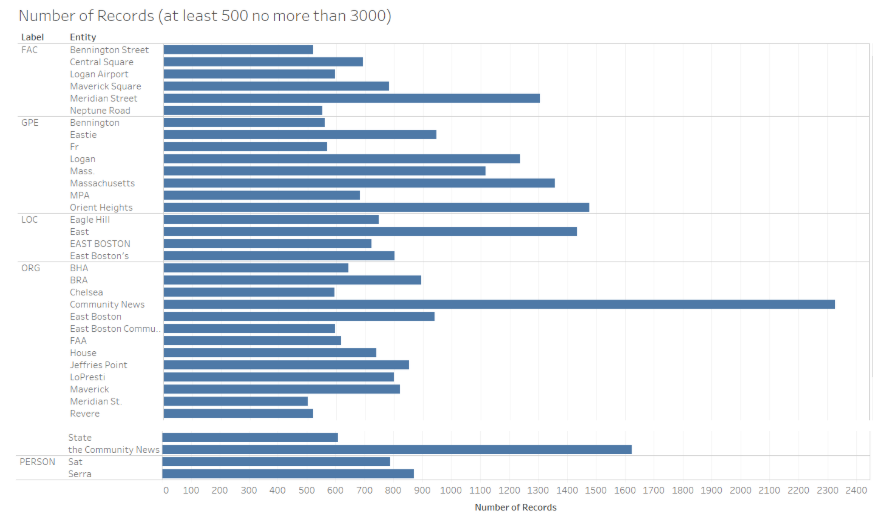
In order to more closely analyze the top entities in each category, I chose to filter the results to show entities which had at least 500 and no more than 3,000 instances. These numbers were chosen in order to filter out both the upper shelf and lower shelf of the results since many entities occurred thousands of times in the data though only entities such as East Boston or Community News (both of which are expected to occur many times) had occurrences above 3,000. Of course, as can be seen in the bar graph below, there are some instances where NLTK is making mistakes (for instance, “East” is categorized as an organization) though there are also many instances were NLTK correctly assigned entity labels.
NLTK
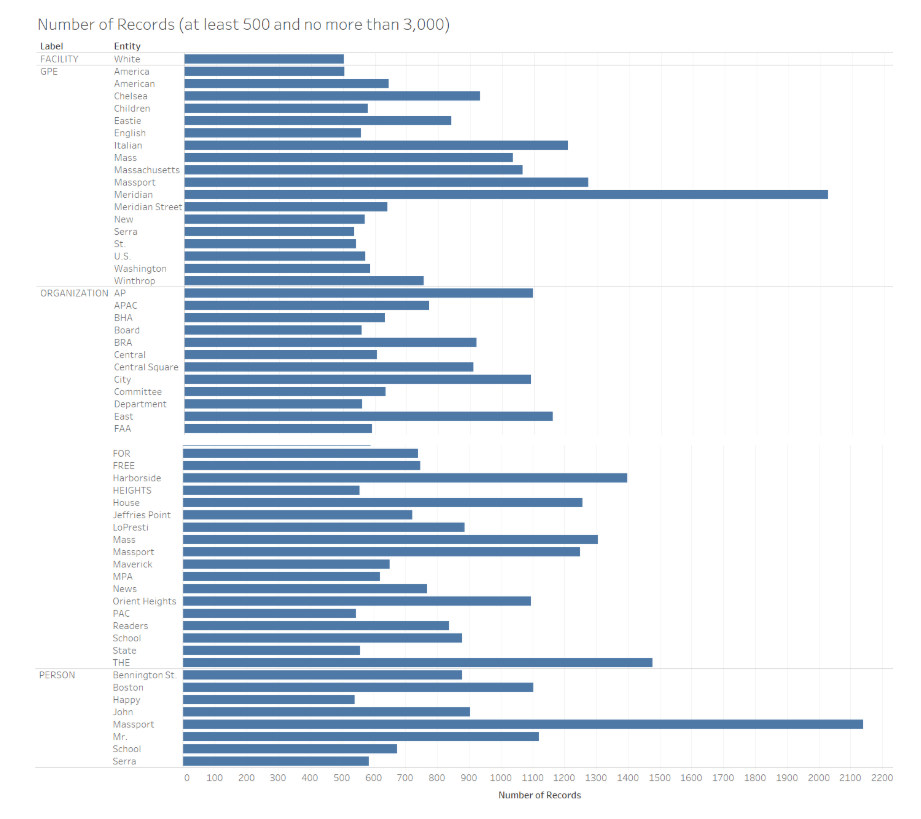
Looking at the same bar graph with spaCy’s results illustrates what I already suspected: that the wider variety of labels would allow for more nuance and accuracy with assignments. Below, you can see a bar graph filtered in a similar way that NLTK’s results were filtered. Notably, this bar graph only includes the labels which spaCY and NLTK share. As you can see, since spaCy has more variety of labels, entities such as “East Boston” labeled as “LOC” (Location) have fewer than 3,000 occurences which makes occurrences between 500 and 3,000 has it is for NLTK’s results at filtering out entities we are not interested in such as East Boston and Community News.
SpaCy
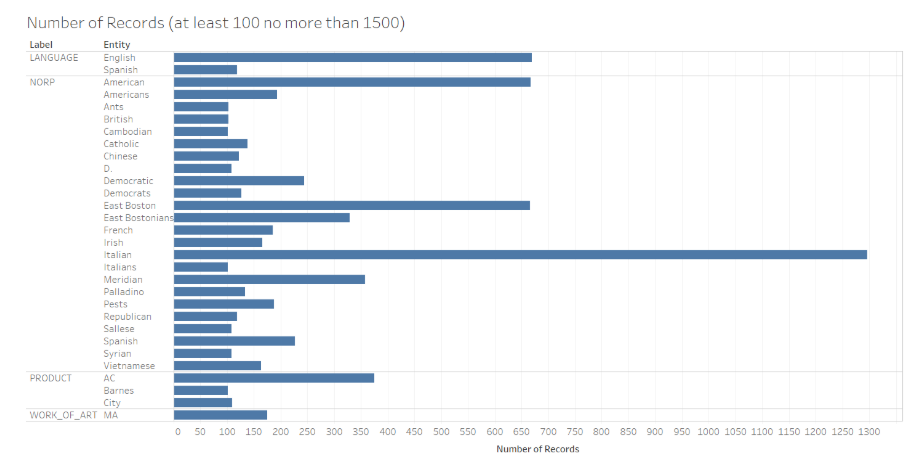
By tweaking the filtering numbers slightly, I determined that looking for occurences between 100 and 1,500 were most effective for spaCy’s results. Below, you can see a bar graph for entities which are not shared between spaCy and NLTK. As you can see, most instances of East Boston and Community News have been effectively filtered out, though there is still one occurence. With this filtering metric, we can begin to see some of the more significant occurrences, such as the high occurrence of English and Spanish as well as at least 100 mentions of “Chinese,” “Catholic,” “Cambodian,” “Syrian,” and many other nationalities and religious entities one might not suspect for a local newspaper coming out of East Boston.
Labels Not in NLTK
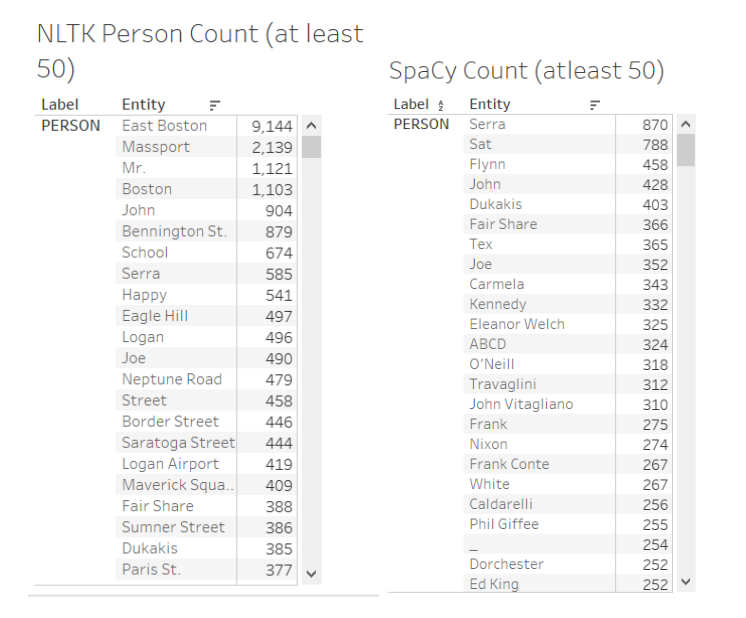
Turning now to comparing the accuracy of both NLTK and spaCy, I filtered the results to only show me entities labeled as “person” which had at least 50 occurences. The top results for both NLTK and spaCy are detailed below. As you can see, while both NLTK and spaCy often make mistakes, the results of spaCy are much more accurate since most of the entities NLTK determines to be people aren’t people, at all, but rather locations and even street addresses.
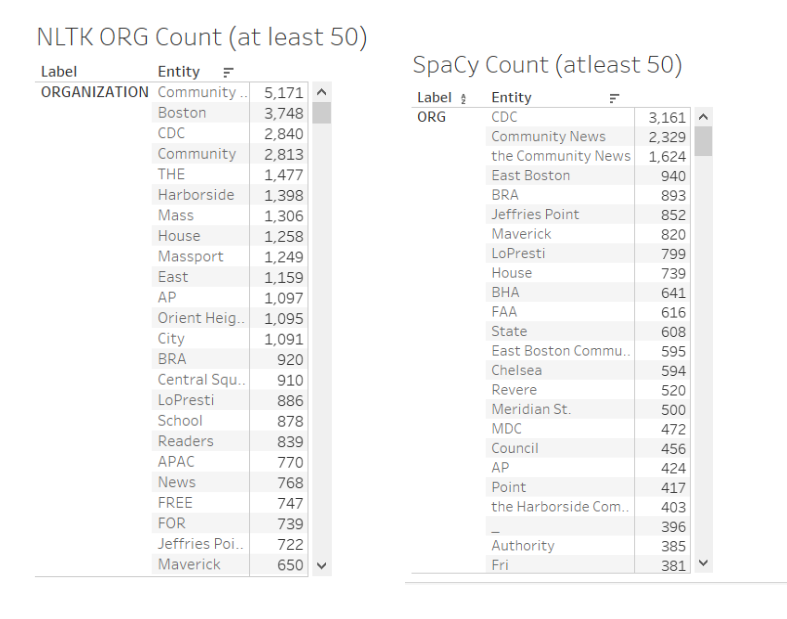
Similarly, looking at a comparison of the Organization tag, you can see that NLTK is often tagging “Community,” “FREE,” “News,” “House,” and other such labels as organizations when they are not. SpaCy is often making the same type of mistakes, however, in the case of the Organization tag. Additionally, while NLTK and spaCy share many labels, spaCy’s counts are significantly variant. For example, while NLTK detects 2,840 occurences of the CDC, spaCy detects 3,161 occurences of the CDC. However, while these counts vary, the high positioning of the CDC in both lists suggests that the CDC is a significant organization in the East Boston Community news, though for what purpose is still unclear.
Future Work
As this project progresses, I hope to explore other named entity recognition options that have more support for multilingual documents. While both NLTK and Spacy have some support for Italian, I want to ensure that any other documents we may work with in other languages have the same, if not similar, entity recognition accuracy. Support for non-English languages is a crucial component of any computational practices the BRC implements. Polyglot is an open-source, natural language processing pipeline which supports named entity recognition in forty languages, and its approach to language detection is very precise. As some experiments show, Polyglot appears to be relatively balanced when it comes to accuracy and sensitivity, though it only recognizes three categories of entities (people, locations, and organizations). In combination with shifting our focus to open source packages which have a more expansive capacity for language recognition, we also hope to cross-compare our results to hand-annotated issues of the East Boston Community News in order to determine the efficacy and robustness of these three NER packages.
Additionally, as we begin to solidify the kinds of research questions we are asking of community newspapers, I have begun to test out various word embedding models for the East Boston Community News. My hope is that in using this methodology, I can begin to understand in what context these named entities are being used and how this context may get at questions regarding how the newspaper sees itself. The code for each of these sub-projects will be made available through Github and we also plan to implement the code on other Boston community newspapers we gain access to.